
SALUD
En nuestro mundo hiper-conectado, nos enfrentamos a un dilema crítico: ¿cómo podemos aprovechar el poder de la inteligencia artificial, que se nutre de datos, sin sacrificar nuestro derecho fundamental a la privacidad?
El aprendizaje automático tradicional suele requerir conjuntos de datos masivos y centralizados, lo que genera importantes riesgos de seguridad y problemas de privacidad.
Pero un enfoque revolucionario está cambiando las reglas del juego.
Se trata de la IA federada, también conocida como aprendizaje federado. Esta innovadora técnica ofrece una potente solución que nos permite crear modelos de IA más inteligentes de forma colaborativa sin centralizar nunca los datos confidenciales de los usuarios.
En esencia, la IA federada es un método de aprendizaje automático descentralizado. En lugar de obligarle a cargar sus datos en un servidor central para su análisis, este enfoque lleva el modelo de IA a sus datos.
Piénsalo así: un entrenador jefe quiere mejorar la estrategia del equipo sin reunir a todos los jugadores en una sala. En su lugar, el entrenador envía a sus ayudantes a casa de cada jugador.
Los jugadores entrenan en sus casas y los ayudantes vuelven al entrenador con un resumen de sus impresiones, no con vídeos secretos del entrenamiento. El entrenador principal combina entonces estos comentarios para crear una estrategia maestra para todos.
En esta analogía, los jugadores son dispositivos de usuario (como tu teléfono), el entrenamiento local es el modelo de inteligencia artificial que se entrena con los datos de tu dispositivo, y los comentarios de los entrenadores asistentes son la pequeña actualización encriptada del modelo que se envía de vuelta. Tus datos personales nunca salen de tu "casa".
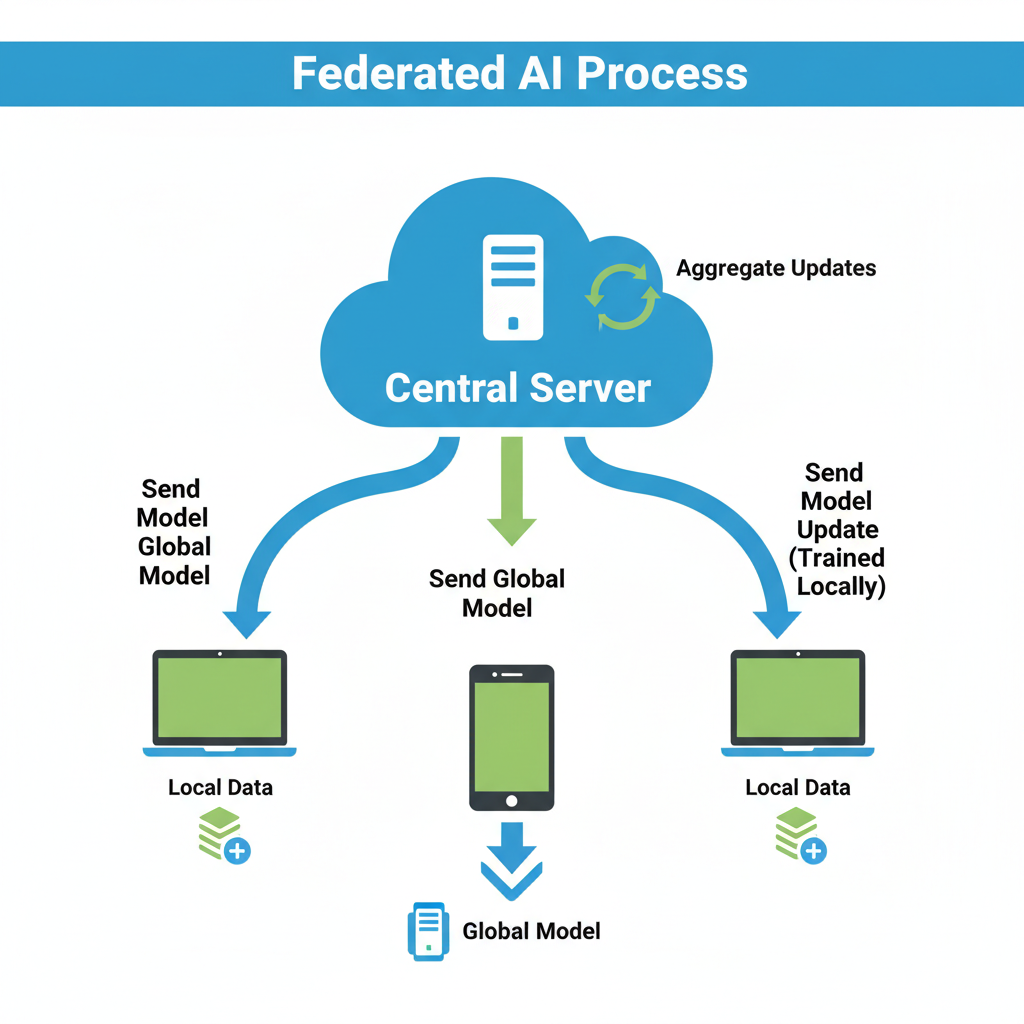
El proceso de aprendizaje federado es un ciclo iterativo diseñado para la privacidad y la eficiencia:
Distribución: Un servidor central comienza con un modelo genérico de IA y lo envía a múltiples dispositivos de usuario (clientes).
Entrenamiento local: El modelo se entrena directamente en cada dispositivo utilizando sus datos locales. Estos datos en bruto nunca salen del dispositivo.
Actualización encriptada: cada dispositivo envía un pequeño resumen encriptado de sus aprendizajes (actualizaciones de los parámetros del modelo) al servidor, no los datos en sí.
Agregación segura: El servidor combina estas actualizaciones cifradas de muchos usuarios para crear un modelo global único y mejorado.
Iteración: Este modelo más inteligente y refinado se envía de vuelta a los dispositivos, y el ciclo se repite, mejorando progresivamente el modelo.
Las ventajas de este enfoque descentralizado están transformando las posibilidades de la IA.
Esta es la piedra angular del aprendizaje federado. Al mantener los datos en bruto localizados, se reduce drásticamente el riesgo de filtración de datos y la exposición de información confidencial como historiales médicos, transacciones financieras o mensajes privados.
Transmitir sólo pequeñas actualizaciones de modelos agregados minimiza la superficie de ataque. Técnicas avanzadas como la agregación segura y la privacidad diferencial añaden capas adicionales de protección, haciendo extremadamente difícil que los actores maliciosos comprometan el sistema.
Muchas organizaciones, como hospitales o bancos competidores, tienen prohibido legal o comercialmente compartir datos. La IA federada les permite colaborar en la creación de modelos predictivos superiores (por ejemplo, para el diagnóstico de enfermedades o la detección de fraudes) sin compartir nunca sus datos confidenciales.
Sin necesidad de transferir y almacenar petabytes de datos de usuarios en servidores centrales, las empresas pueden reducir significativamente el ancho de banda de la red y los costes de infraestructura.
El aprendizaje federado no es sólo una teoría; ya está impulsando funciones que usted utiliza a diario:
Teléfonos inteligentes: Mejora de los teclados predictivos (como Gboard de Google), el reconocimiento de voz y las fuentes de contenido personalizadas sin cargar tus conversaciones privadas o patrones de uso.
Sanidad: Permitir a los hospitales entrenar conjuntamente una inteligencia artificial más precisa para la detección del cáncer, aprendiendo de las exploraciones de diversos pacientes y respetando la estricta confidencialidad de los mismos (HIPAA).
Finanzas: Mejorar la detección del fraude permitiendo a los bancos compartir información sobre amenazas sin revelar datos confidenciales de las transacciones de los clientes.
Vehículos autónomos: Mejorar los modelos de conducción autónoma aprendiendo de las experiencias de conducción reales de toda una flota, sin transmitir grandes cantidades de datos brutos de sensores.
A pesar de su inmenso potencial, la implantación de la IA federada conlleva una serie de retos únicos.
Los datos de los dispositivos de los usuarios rara vez son uniformes. Se trata de datos no independientes e idénticamente distribuidos (Non-IID), lo que significa que varían enormemente en distribución, cantidad y contenido. Esto puede sesgar el modelo o ralentizar su entrenamiento, y requiere algoritmos sofisticados para gestionarlo con eficacia.
La comunicación constante entre el servidor y, potencialmente, millones de dispositivos puede suponer un importante cuello de botella. El ancho de banda limitado, la latencia de la red y el coste de la transferencia de datos son obstáculos prácticos importantes.
Aunque preserva la privacidad, el sistema no es invulnerable. Los actores malintencionados podrían intentar ataques de inferencia para aplicar ingeniería inversa a los datos de las actualizaciones del modelo o utilizar el envenenamiento de datos para corromper intencionadamente el modelo global.
Los dispositivos participantes tienen una amplia gama de hardware (CPU, memoria), estabilidad de red y duración de la batería. Esto puede dar lugar a "rezagados" -dispositivos más lentos que retrasan el proceso de entrenamiento de todos los demás- y requiere un sistema que sea robusto frente a los abandonos de clientes.
P1: ¿Cuál es la principal diferencia entre la IA federada y la IA tradicional? La principal diferencia es la ubicación de los datos. La IA tradicional requiere que los datos se recopilen y almacenen en una ubicación central para el entrenamiento. La IA federada invierte esta situación, llevando el modelo de entrenamiento a las fuentes de datos descentralizadas, garantizando que los datos en bruto nunca salgan del dispositivo del usuario.
P2: ¿Es la IA federada completamente segura y privada? Es mucho más privada y segura que los métodos centralizados. Sin embargo, no es inmune a ataques sofisticados. Por eso los investigadores la combinan con otras tecnologías que mejoran la privacidad, como la privacidad diferencial y la agregación segura, para crear defensas sólidas.
P3: ¿Qué empresas utilizan el aprendizaje federado? Grandes empresas tecnológicas como Google (para Gboard) y Apple (para Siri) son pioneras bien conocidas. Además, empresas especializadas en IA como Sherpa.ai, conocida por su plataforma de IA que preserva la privacidad, y NVIDIA (con su plataforma Clara para la atención sanitaria) también están a la vanguardia del desarrollo y la implantación de soluciones de aprendizaje federado.
La IA federada representa un cambio monumental hacia un futuro más ético, seguro y colaborativo para la inteligencia artificial. Al resolver el conflicto central entre los algoritmos ávidos de datos y la privacidad del usuario, allana el camino para innovaciones que antes creíamos imposibles.
Aunque aún quedan retos por superar, los rápidos avances en este campo prometen convertir el aprendizaje federado en un estándar para la próxima generación de sistemas inteligentes.
