
SALUD
n una era de amenazas cibernéticas implacables y un panorama de privacidad global cada vez más estricto, las empresas se enfrentan a un desafío crítico: ¿cómo pueden aprovechar enormes cantidades de datos para construir defensas sólidas impulsadas por IA sin violar la confianza del cliente ni infringir la ley?
La respuesta está en un paradigma tecnológico transformador: El aprendizaje federado.
Esta guía explora cómo este enfoque descentralizado de la IA, también conocido como IA colaborativa, está revolucionando la ciberseguridad. Cubriremos sus aplicaciones clave, su papel en el cumplimiento global y los beneficios económicos del mundo real para las empresas.
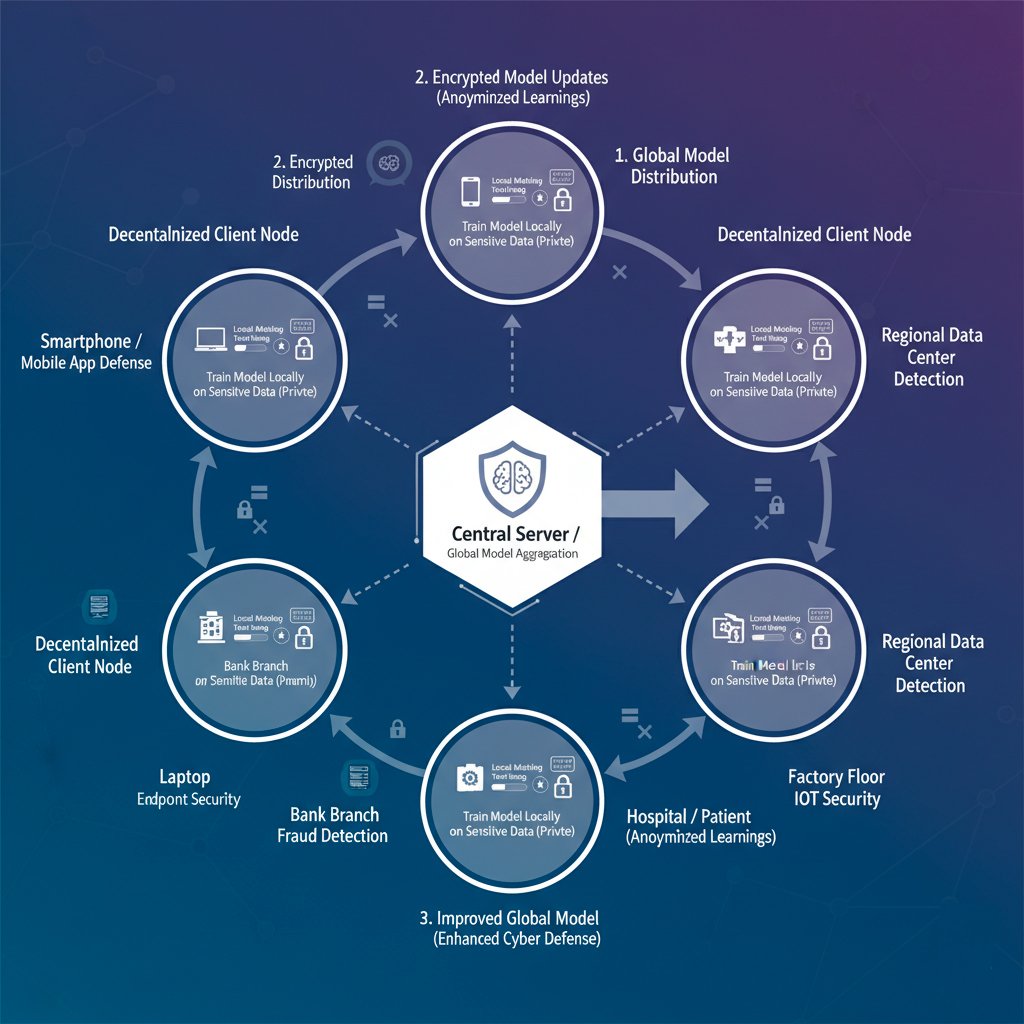
En esencia, el aprendizaje federado es una técnica descentralizada de aprendizaje automático que entrena un algoritmo en varios dispositivos o servidores independientes sin intercambiar nunca los datos en bruto.
En lugar de agrupar la información sensible en un único lago de datos vulnerable para su análisis, el proceso se invierte:
Un servidor central envía un modelo básico de IA a dispositivos individuales (o "nodos").
Cada nodo entrena el modelo con sus propios datos locales, creando una versión mejorada.
Los aprendizajes de estos modelos locales -pequeñas actualizaciones anónimas- se encriptan y se envían de vuelta.
El servidor central agrega estas actualizaciones para crear un "modelo global" más inteligente y refinado, que luego se distribuye a todos los nodos.
Este enfoque de modelado que preserva la privacidad garantiza que los datos confidenciales nunca abandonen su fuente, ofreciendo una potente solución al clásico dilema de privacidad frente a seguridad.
Este innovador método de IA se está aplicando activamente en áreas críticas de la ciberseguridad para crear mecanismos de defensa más inteligentes y adaptables contra amenazas como el malware, el ransomware y el phishing.
El tráfico de red es muy sensible y varía según la región. Un IDS basado en un modelo de inteligencia de enjambre permite a los nodos individuales de la red entrenar modelos en su tráfico local para identificar anomalías. Estos datos localizados se combinan para construir un modelo global que puede reconocer ataques sofisticados en varias fases y amenazas de día cero que serían invisibles para un sistema aislado.
Para combatir el malware en constante evolución, los equipos de seguridad pueden utilizar un marco de inteligencia distribuida para entrenar modelos de detección de forma colaborativa. Cada participante entrena un modelo en sus conjuntos de datos locales de archivos maliciosos y benignos. Esto les permite crear un clasificador potente y actualizado sin compartir código propietario ni archivos de clientes, una ventaja crucial para proteger aplicaciones como la banca móvil.
Las instituciones financieras están utilizando análisis descentralizados para detectar tramas de fraude complejas. Al entrenar un modelo de detección de fraudes en datos de transacciones distribuidas, los bancos pueden identificar patrones sutiles indicativos de blanqueo de dinero o fraude con tarjeta no presente sin compartir los registros financieros confidenciales de los clientes.
Un factor clave para adoptar el aprendizaje federado es su alineación inherente con los principios básicos de las principales normativas de protección de datos en todo el mundo.
GDPR (Unión Europea): Apoya directamente la minimización de datos y la limitación de propósitos, ya que los datos en bruto nunca se recopilan de forma centralizada.
CCPA/CPRA (California, EE.UU.): Al no transferir datos personales en bruto, resulta mucho más difícil argumentar que se ha producido una "venta" o "intercambio" de datos, lo que simplifica el cumplimiento.
LGPD (Brasil): Encarna los principios de necesidad y seguridad de los datos, ya que la ausencia de una base de datos central reduce drásticamente la superficie de ataque para una posible violación.
LPRPDE (Canadá): Simplifica la gestión del consentimiento al permitir que los datos se utilicen para mejorar el modelo en el dispositivo sin que se transfieran nunca.
PIPL (China): Proporciona una potente solución a las estrictas normas de transferencia transfronteriza de datos, ya que sólo salen del país las actualizaciones anonimizadas de los modelos, no los datos en bruto.
Adoptar una metodología de IA que dé prioridad a la privacidad, como el aprendizaje federado, proporciona ventajas económicas sustanciales y tangibles para las empresas.
Beneficios económicos cuantificables:
Reducción del coste de las violaciones de datos: Con la violación de datos promedio costando millones, evitar la centralización de datos ahorra directamente dinero en multas potenciales y remediación.
Menores costes de infraestructura: Se elimina el inmenso gasto de construir y mantener un lago de datos central seguro y conforme a las normas para el entrenamiento de IA.
Mayor eficacia operativa: Modelos más precisos significan que los analistas de seguridad pierden menos tiempo en falsos positivos y se pasan por alto menos ataques reales.
Se evitan las amenazas del mundo real:
Explotaciones de día cero: El sistema destaca en la identificación de patrones inusuales de nuevos ataques sin firma conocida.
Campañas de phishing sofisticadas: Las señales débiles procedentes de una red global pueden agregarse para identificar y detener ataques de phishing a gran escala.
Aunque las ventajas son evidentes, la implantación requiere inversión. Consideremos como ejemplo una plataforma líder en este espacio, Sherpa.ai.
Un plazo de implantación realista para una única aplicación de ciberseguridad oscila entre 2 y 5 meses, abarcando la planificación, la configuración de la infraestructura, la integración y la formación inicial del modelo.
Las plataformas empresariales no publican precios, pero una empresa debe presupuestar:
Cuota de licencia de la plataforma: Una cuota anual que probablemente oscile entre 25.000 y más de 1.000.000 de dólares.
Servicios profesionales e integración: Un coste único significativo, potencialmente de 5.000 a más de 500.000 dólares.
Costes internos y mantenimiento continuo: Costes de personal interno y cuotas anuales de soporte.
Una implantación a gran escala puede representar una inversión inicial de entre seis y siete cifras.
1. ¿En qué se diferencia el aprendizaje federado del aprendizaje automático tradicional? La diferencia clave es dónde se procesan los datos. La IA tradicional requiere centralizar los datos para el entrenamiento. El aprendizaje federado lo invierte; envía el modelo al lugar donde se encuentran los datos. Esto mejora fundamentalmente la privacidad y la seguridad.
2. ¿Quién es el propietario de los datos y del modelo final de IA? La propiedad de los datos sigue siendo de la fuente original. El usuario o la organización nunca cede el control de sus datos. El modelo global final, que contiene patrones matemáticos agregados pero no datos brutos, suele ser propiedad de la entidad que orquesta la red.
3. ¿Es seguro el aprendizaje federado frente a los ataques? Aunque ningún sistema es completamente inmune, esta arquitectura descentralizada es muy resistente. Se utilizan medidas de seguridad como la agregación segura y la privacidad diferencial para cifrar y anonimizar las actualizaciones del modelo, lo que dificulta enormemente la ingeniería inversa de los datos de cualquier persona o el envenenamiento del modelo.
4. ¿Qué sectores pueden beneficiarse del aprendizaje federado? Cualquier industria que maneje datos sensibles y distribuidos puede beneficiarse. Por ejemplo, la sanidad (formación con datos de pacientes de distintos hospitales), las telecomunicaciones (detección de fallos en la red) y la fabricación industrial (predicción de fallos en las máquinas).
5. ¿Cuál es el papel del servidor central si nunca ve los datos? El servidor central actúa como orquestador. Distribuye el modelo base, recibe y agrega de forma segura las actualizaciones cifradas del modelo, construye el modelo global mejorado y lo distribuye a los participantes. Gestiona el proceso de aprendizaje sin acceder nunca a los datos sensibles subyacentes.
